What is Starlake ?
Starlake is a configuration only Extract, Load and Transform engine. The workflow below is a typical use case:
- Extract your data as a set of Fixed Position, DSV (Delimiter-separated values) or JSON or XML files
- Define or infer the structure of each POSITION/DSV/JSON/XML file with a schema using YAML syntax
- Configure the loading process
- Start watching your data being available as Tables in your warehouse.
- Build aggregates using SQL, Jinja and YAML configuration files.
Starlake may be used indistinctly for all or any of these steps.
- The
extractstep allows to export selective data from an existing SQL database to a set of CSV files. - The
loadstep allows you to load text files, to ingest FIXED-WIDTH/CSV/JSON/XML files as strong typed records stored as parquet files or DWH tables (eq. Google BigQuery) or whatever sink you configured - The
transformstep allows to join loaded data and save them as parquet files, DWH tables or Elasticsearch indices
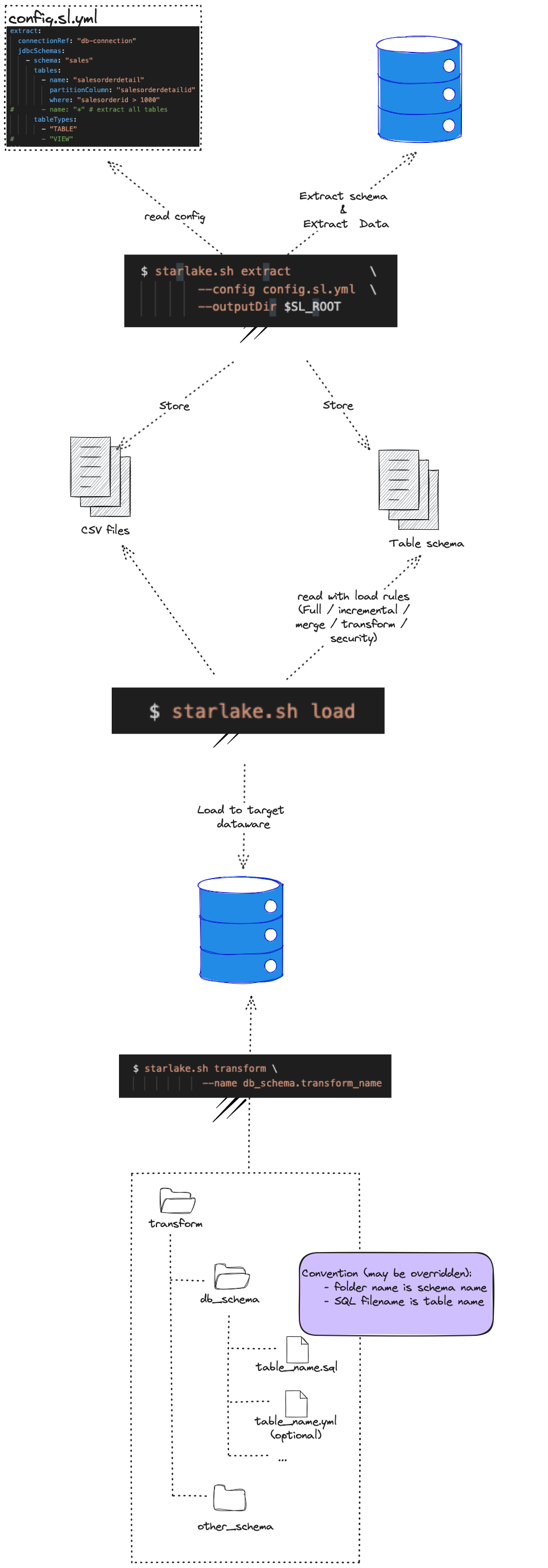
The Load and Transform steps support multiple configurations for inputs and outputs as illustrated in the figure below.

Data Lifecycle
The figure below illustrates the typical data lifecycle in Starlake.
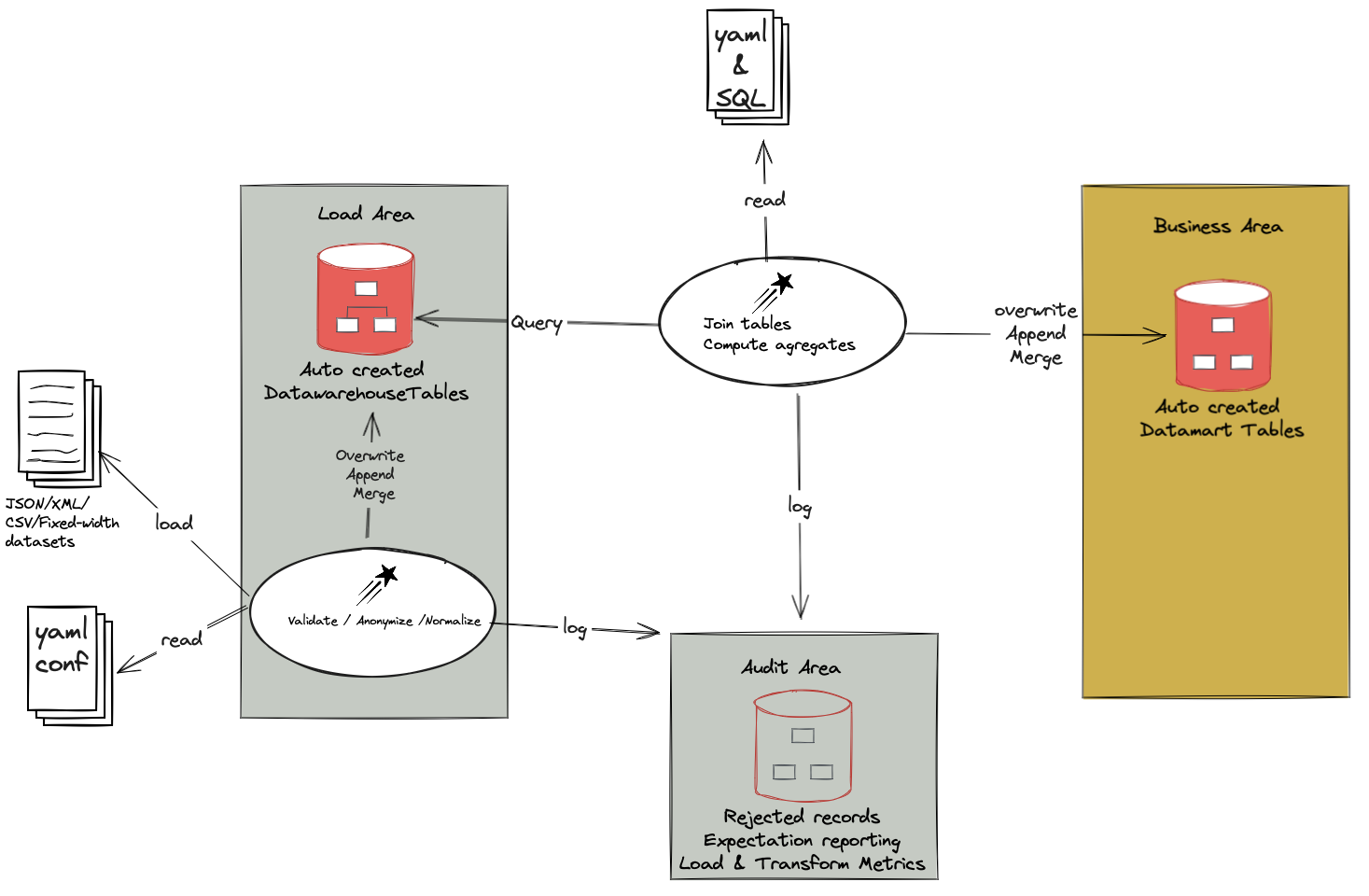
- Landing Area: In this optional step, files with predefined filename patterns are stored on a local filesystem in a predefined folder hierarchy - Pending Area: Files associated with a schema are imported into this area.
- Accepted Area: Pending files are parsed against their schema and records are rejected or accepted and made available in Bigquery/Snowflake/Databricks/Hive/... tables or parquet files in a cloud bucket.
- Business Area: Tables (Hive / BigQuery / Parquet files / ...) in the working area may be joined to provide a holistic view of the data through the definition of transformations.
- Data visualization: parquet files / tables may be exposed in data warehouses or elasticsearch indices through an indexing definition
Input file schemas, ingestion rules, transformation and indexing definitions used in the steps above are all defined in YAML files.
Data Extraction
Starlake provides a fast way to extract, in full or incrementally, tables from your database.
Using parallel load through a JDBC connection and configuring the incremental fields in the schema, you may extract your data incrementally. Once copied to the cloud provider of your choice, the data is available for further processing by the Load and Transform steps.
The extraction module support two modes:
- Native mode: Native database scripts are generated and must be run against your database.
- JDBC mode: In this mode, Starlake will spawn a number of threads to extract the data. We were able to extract an average of 1 million records per second using the AdventureWorks database on Postgres.
Data Loading
Usually, data loading is done by writing hand made custom parsers that transform input files into datasets of records.
Starlake aims at automating this parsing task by making data loading purely declarative.
The major benefits the Starlake data loader bring to your warehouse are:
- Eliminates manual coding for data loading
- Assign metadata to each dataset
- Expose data loading metrics and history
- Transform text files to strongly typed records without coding
- Support semantic types by allowing you to set type constraints on the incoming data
- Apply privacy to specific fields
- Apply security at load time
- Preview your data lifecycle and publish in SVG format
- Support multiple data sources and sinks
- Starlake is a very, very simple piece of software to administer
The Load module supports 2 modes:
- The native mode, the fatest one will use the target database capabilities to load the data and apply all the required transformations. For example, on BigQuery, starlake use the Bigquery Load API
- The Spark mode will use Spark to load the data. This mode is slower than the native mode but is the most powerful one and is compatible with all databases. Please note that this mode does not require setting up a Spark cluster, it run out of the box in the starlake docker image.
The table below list the features supported by each mode, the one that meet your requirements depend on the quality of your source and on the audit level you wish to have:
| File formats | Spark | Native |
|---|---|---|
| CSV | x | x |
| CSV with multichar separator | x | |
| JSON Lines | x | x |
| JSON Array | x | |
| XML | x | |
| POSITION | x | x |
| Parquet | x | x |
| Avro | x | x |
| Kafka | x | |
| Any JDBC database | x | |
| Any Spark Source | x | |
| Any char encoding including chinese, arabic, celtic ... | x |
| Error Handling Levels | Spark | Native |
|---|---|---|
| File level | x | x |
| Column level reporting | x | |
| Produce replay file | x | |
| Handle unlimited number of errors | x |
| Features | Spark | Native |
|---|---|---|
| rename domain | x | x |
| rename table | x | x |
| rename fields | x | x |
| add new field (scripted fields) | x | x |
| Apply privacy on field (transformation) | x | x |
| Validate type | x | x |
| Validate pattern (semantic types) | x | |
| Ignore fields | x | x |
| remove fields after transformation | x | x |
| date and time fields any format | x | - |
| keep filename | x | x |
| Partition table | x | x |
| Append Mode | x | x |
| Overwrite Mode | x | x |
| Merge Mode | x | x |
| Pre/Post SQL | x | x |
| Apply assertions | x |
| Security | Spark | Native |
|---|---|---|
| Apply ACL | x | x |
| Apply RLS | x | x |
| Apply Tags | x | x |
Data Transformation
Simply write standard SQL et describe how you want the result to be stored in a YAML description file. The major benefits Starlake bring to your Data transformation jobs are:
- Write transformations in regular SQL or python scripts
- Use Jinja2 to augment your SQL scripts and make them easier to read and maintain
- Describe where and how the result is stored using YML description files (or even easier using an Excel sheet)
- Apply security to the target table
- Preview your data lifecycle and publish in SVG format
Illustration
The figure below illustrates how all the steps above are combined using the starlake CLI to provide a complete data lifecycle.